多くの変数から重要な変数をスクリーニングする方法 第1回: 説明変数のスクリーニング
増川 直裕
ハードウェアや機器等の進歩により、近年は多くのデータが取得できるようになったといわれています。例えばモノを製造する段階ではセンサーなどの機器から部品や工程に関する多くのデータを得られますし、製品の開発段階でも材料と特性に関するさまざまな値を測定してデータ化できます。
これらのデータをうまく活用することが、良い製品をつくる際のカギとなってきます。
しかし測定値を数百、数千も含むような大規模データをどのように分析して良いかはとても悩むところです。例えば製品の歩留まりに影響する部品や工程を見つけることを目的とした場合、数千の部品や工程変数があれば、そこから重要な変数を見つけるのに重回帰分析を用いても、多重共線性の問題が発生しうまくいかなかったりします。
■スクリーニングして、まず精鋭を選ぶ
JMPは大量の変数を分析する手法を多数搭載しておりますが、その中でも多くの変数から重要な変数を抽出する「スクリーニング」の機能が便利です。
ここでいうスクリーニングとは、フィルタを介してふるいにかけるようなイメージです。

ふるいにかけて選ばれた変数は、大量の変数の中から選ばれた精鋭です。その選ばれた精鋭を使って、さらに詳細な分析を行なうことも考えられます。
■JMPのスクリーニングトリオ
JMPでは、「スクリーニング」という独立したメニューがあり、その中にはスクリーニングに関するさまざまなメニューがありますが、大量の変数があるデータの場合、次の3つのスクリーニング(応答、工程、説明変数)のメニューがお勧めです。

これらはデータの性質や目的などによって選んでいただくことになりますが、私はこれら3つのスクリーニング機能を勝手に「スクリーニングトリオ」と呼んでいます。JMPで公認している呼び方ではないので、あしからず...
本ブログシリーズでは、スクリーニングトリオとなる3つのスクリーニングについて、特徴や利用例をご紹介いたします。
今回の第1回目は、説明変数のスクリーニングです。
■説明変数のスクリーニング
目的変数(Y) に対して、大量の説明変数(X) があるときに有効な機能です。先ほどの例に示したように、ロットごとの歩留まりをYとし、それに影響する部品や工程の変数を見つけていくといった用途で使うと良いでしょう。
具体的な使用例を、JMPのサンプルデータとして搭載している「Band Data」を用いて示します。
印刷機の不具合と、印刷機の種類や工程との関係をみるデータです。
オレンジ色で示した列(印刷縞の有無)が目的変数で、印刷における不具合(band)と不具合なし(noband)を示します。
対して黄色で示した列が説明変数となり、32個の印刷機や印刷工程の情報などが取得されています。
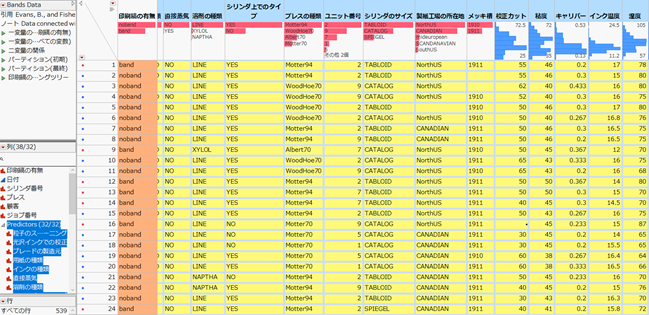
このとき、印刷縞の有無を32個の説明変数で予測するロジスティック回帰を実行してみます。JMPで実施すると次のようなレポートが表示されます。

各説明変数の回帰係数が「パラメータ推定値」として表示されていますが、ところどころ “不安定” と表示されています。実は、このデータでは回帰分析で起こり得る多重共線性が発生しており、推定値に対する(標準)誤差が大きいため、結果としては望ましくないです。
多重共線性を対処する方法としてステップワイズ法を使うことなども考えられますが、ここでは、説明変数のスクリーニングを使ってみます。
■スクリーニングの結果
JMPのメニューから [分析] > [スクリーニング] > [説明変数のスクリーニング] を選択し、次のようにYとX(32個)を指定します。

すると、次のように説明変数の寄与度(band, nobandを分ける変数としてどれぐらい寄与しているか)と、寄与度に基づいて求められた寄与割合と順位のレポートが表示されます。

レポートの中で、寄与度の高い変数が、目的変数Yを説明する変数として重要と考えられます。
そのため、この例では「溶剤(%)」、「インク(%)」、「プレス速度」の順に印刷縞の有無を説明する変数として重要であることがいえます。すなわち、これらの変数をうまく制御することができれば、不具合であるbandの割合を減らせる可能性があります。
ただし、これらの変数が制御できたとしても、どのように制御したら良いのかについてスクリーニングの結果だけではわかりません。溶剤の割合が重要であるといっても、結局何%にしたらよいのかは分からないのです。
そこで、寄与度が高い上位5つの変数だけを使って再度ロジスティック回帰を実行してみます。以下のように、レポート上で上位5つの変数を選択(青色に反転)すると、データテーブルでもその変数が選択された状態になります。

JMPではデータテーブルで変数が選択されていると、それらの変数だけをロジスティック回帰における説明変数に指定できます。
以下はスクリーニングされた5つの変数を使ったロジスティック回帰を行ったときのレポートです。今回は、先ほど表示されていた「不安定」という表示がなくなったので、多重共線性が発生していないようです。

JMPでは、「予測プロファイル」というグラフィカルな予測レポートが表示されますので、重要な変数の値を変更したときのbandが起こる予測確率をインタラクティブに調べることができます。
予測プロファイルでは、説明変数を横軸に、説明変数の値(赤色で表示)に対するYの予測確率が縦軸に示されます。
以下の予測プロファイルでは、プレスの種類=”Motter70”、粘度 = 35,・・・, 溶剤=40 という値をとるとき、nobandになる確率が0.993 (= 99.3%)であることを示しています。

あくまでもデータから得られた予測確率なので、この設定だと確実に不具合が減るというわけではありませんが、この条件で印刷機を運用してみて、本当に不具合が減るのか確認してみても良いでしょう。
■結局、「説明変数のスクリーニング」は何をやっているのか?
説明変数のスクリーニングでは、説明変数に寄与度をつけて重要な変数の順に順位付けしていますが、結局どのような方法で順位付けしているのでしょうか。
実は、ランダムフォレスト(JMPでは”ブートストラップ森” と呼んでいる)という機械学習でよく用いられる手法を使って、各変数の寄与度を算出しているのです。ランダムフォレストとは、小さいツリーモデルをたくさん作成し、それらを合わせて予測精度を高めることを目指したモデルになります。
説明変数のスクリーニングでは、デフォルトの設定でツリーの数を100としているので、100個のツリーモデルを作成していることになります。

注意点を挙げると、ランダムフォレストはランダムという言葉が示す通り、復元抽出するサンプルの組み合わせによって、作成されるツリーは微妙に変わってきます。そのため同じ分析を何度か実施しても、毎回全く同じ結果になるとは限りません。同じ結果にしたい場合は、「乱数シード値の設定」に、何らかの値 (123456 など)をシードとして入力します。
次回の第2回では、「応答のスクリーニング」をご紹介します。