分析前の再設定が不要に!カスタマイズ設定を保存できる「プラットフォームプリセット」
※今回の内容はYouTube動画でもご紹介しています。
この記事では、JMP 18の新機能「プラットフォームプリセット」をご紹介します。頻繁に使用するレポート出力のカスタマイズ(色や軸の設定等)を保存できるので、次回の分析の際に再設定する手間が省けたり、他の人と共有できたりして便利です。
毎回セットアップ作業の繰り返しに浪費していた時間と労力を削減できるのが大きなメリットです。
それでは早速試してみましょう。今回はタブレット製造のサンプルデータを使ってご紹介します。
■レポートのカスタマイズとその保存
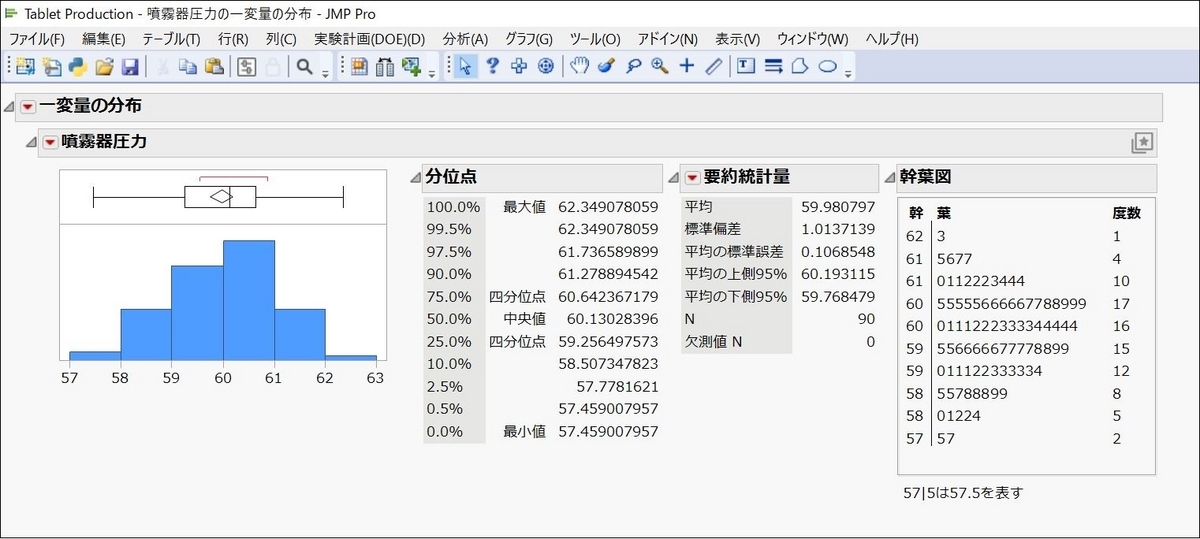
JMPを起動後、「ヘルプ」>「サンプルデータフォルダ」と進み、「Tablet Production」を選択します。「分析」>「一変量の分布」と進み、「噴霧器圧力」を「Y,列」に入れて「OK」をクリックします。
次に、表示されたレポートをカスタマイズしてみます。まず、ヒストグラムを横向きにして色を変えてみます(「噴霧器圧力」横の赤い三角形のオプションから「表示オプション」>「横に並べる」&「ヒストグラムオプション」>「ヒストグラムの色」)。さらに、幹葉図も追加します(赤い三角形のオプションから「幹葉図」を選択)。
すると、下のようにレポートがカスタマイズされたはずです。
次に、このカスタマイズを保存します。
ここで画面右上部に見えるのが「プラットフォームプリセット」のアイコンです。
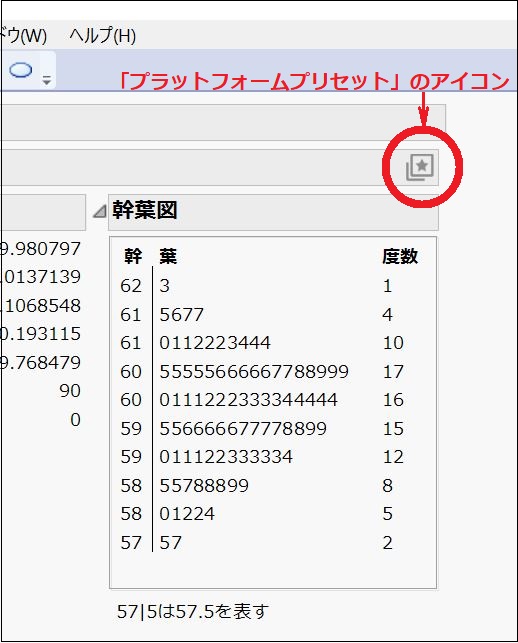
これをクリックしてみましょう。
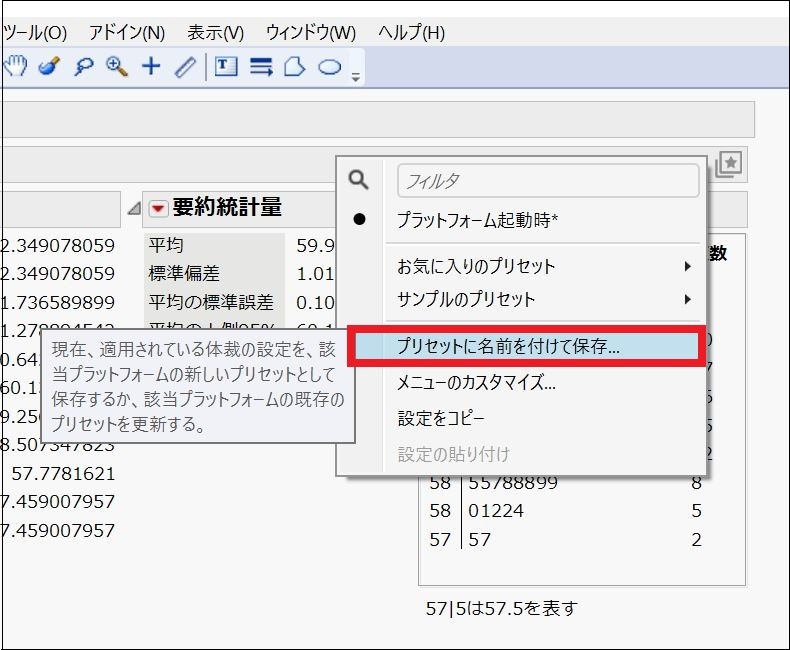
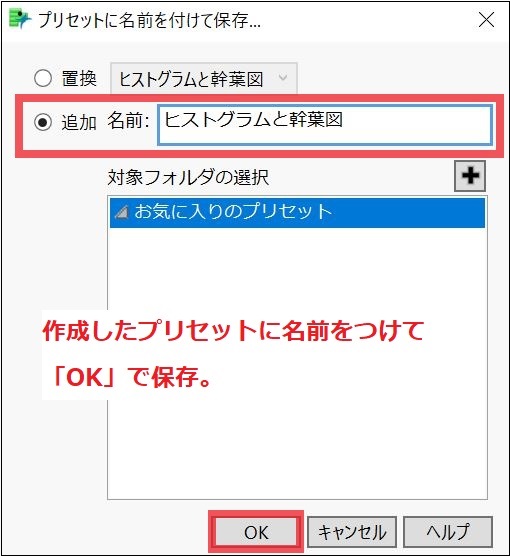
リストの「プリセットに名前を付けて保存」を選び、適当な名前を付けたら(ここでは「ヒストグラムと幹葉図」にします)、「OK」をクリックして保存できます。
■プリセットの適用
保存したプリセットは、他のデータテーブルや列に適用できます。先ほどのデータテーブルの別の列(「溶出」)で試してみましょう。
データテーブルに戻り、「分析」>「一変量の分布」と進み、「溶出」を「Y,列」に入れて「OK」を押します。
右のアイコンから、「お気に入りのプリセット」>「ヒストグラムと幹葉図」と進めて、先ほど保存したプリセットを適用してみましょう。

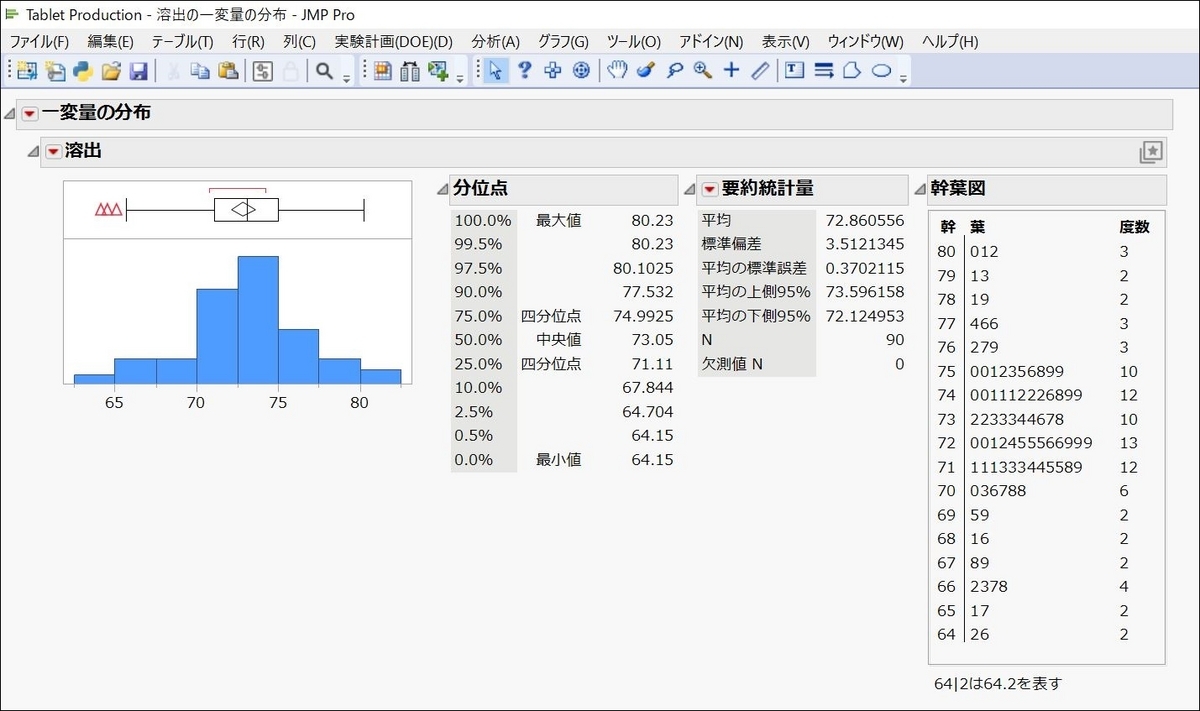
最初のレポート(「噴霧器圧力」)と2番目のレポート(「溶出」)を比べると、同じ設定が適用されているのが分かりますね。
最初のレポート(「噴霧器圧力」)
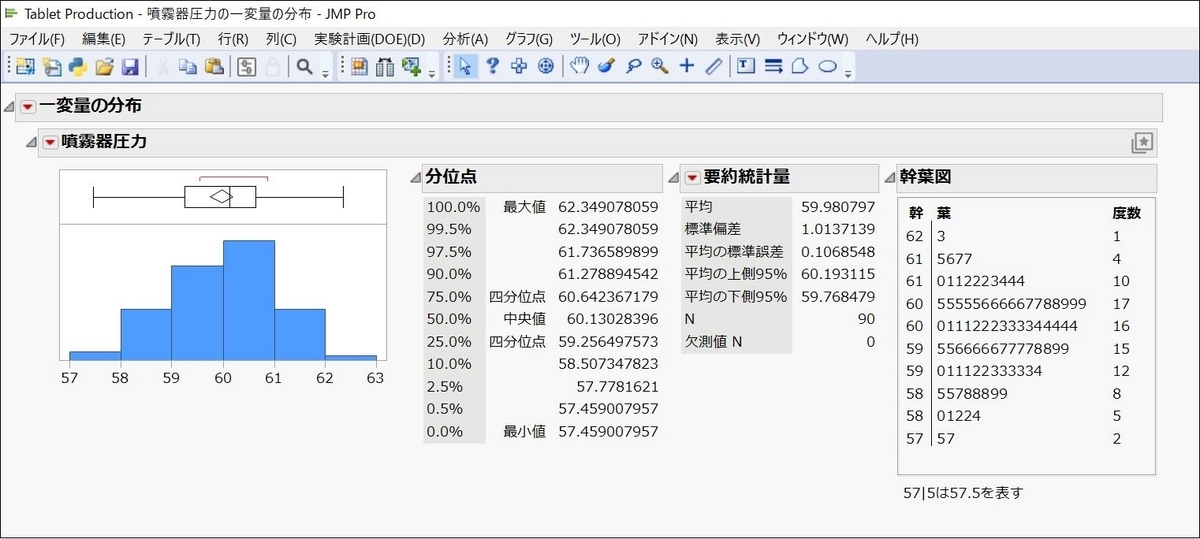
2番目のレポート(「溶出」)
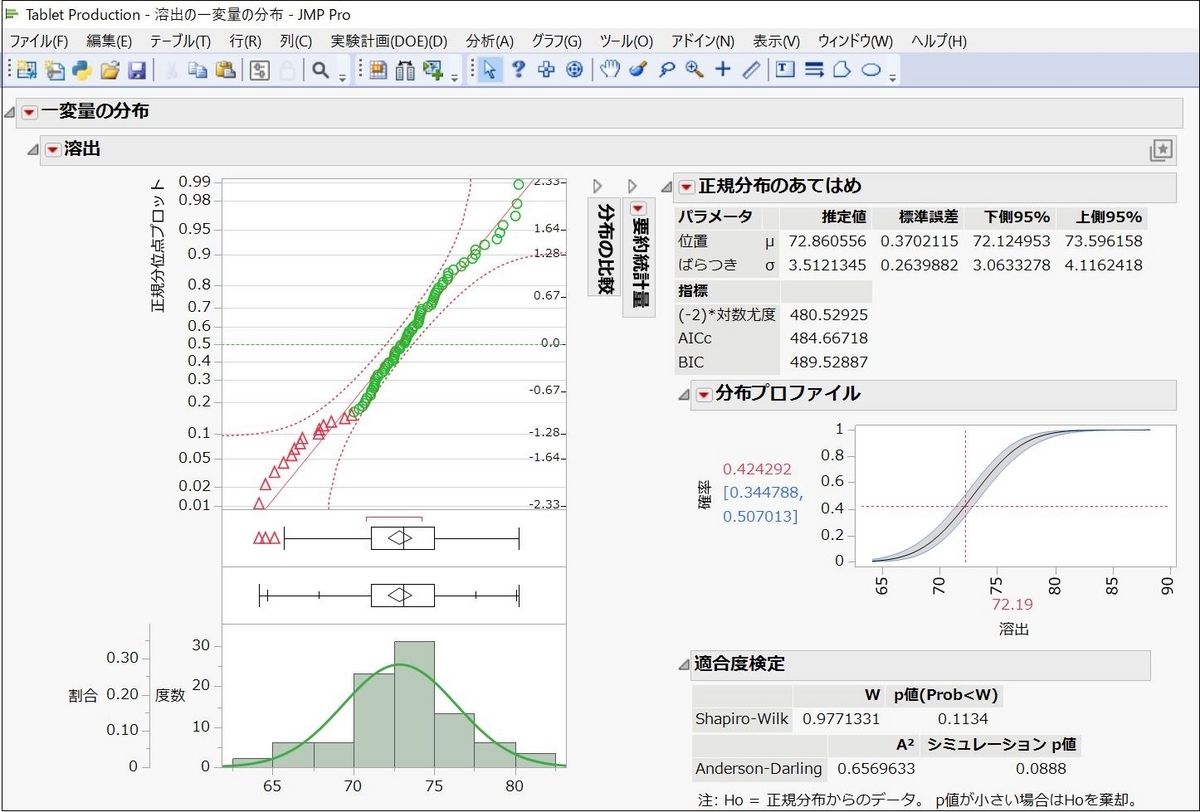
このようにご自身でプリセットを作成してもいいですし、あらかじめ用意されているサンプルを使うのも便利です。

※「正規性をチェック」のサンプル例
■プリセットの共有
さらに、作成・保存したプリセットはファイルに書き出して共有できます。
・書き出し
「ファイル」 > 「環境設定」の「プラットフォームのプリセット」を開き、「書き出
し」をクリックして保存。
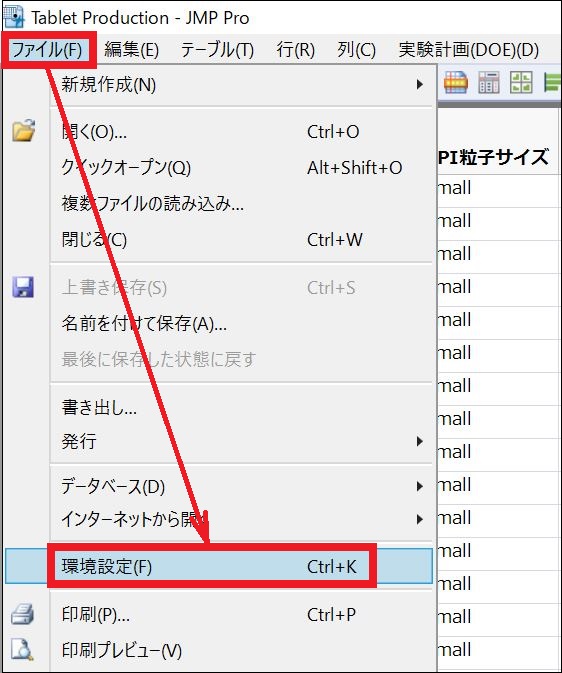

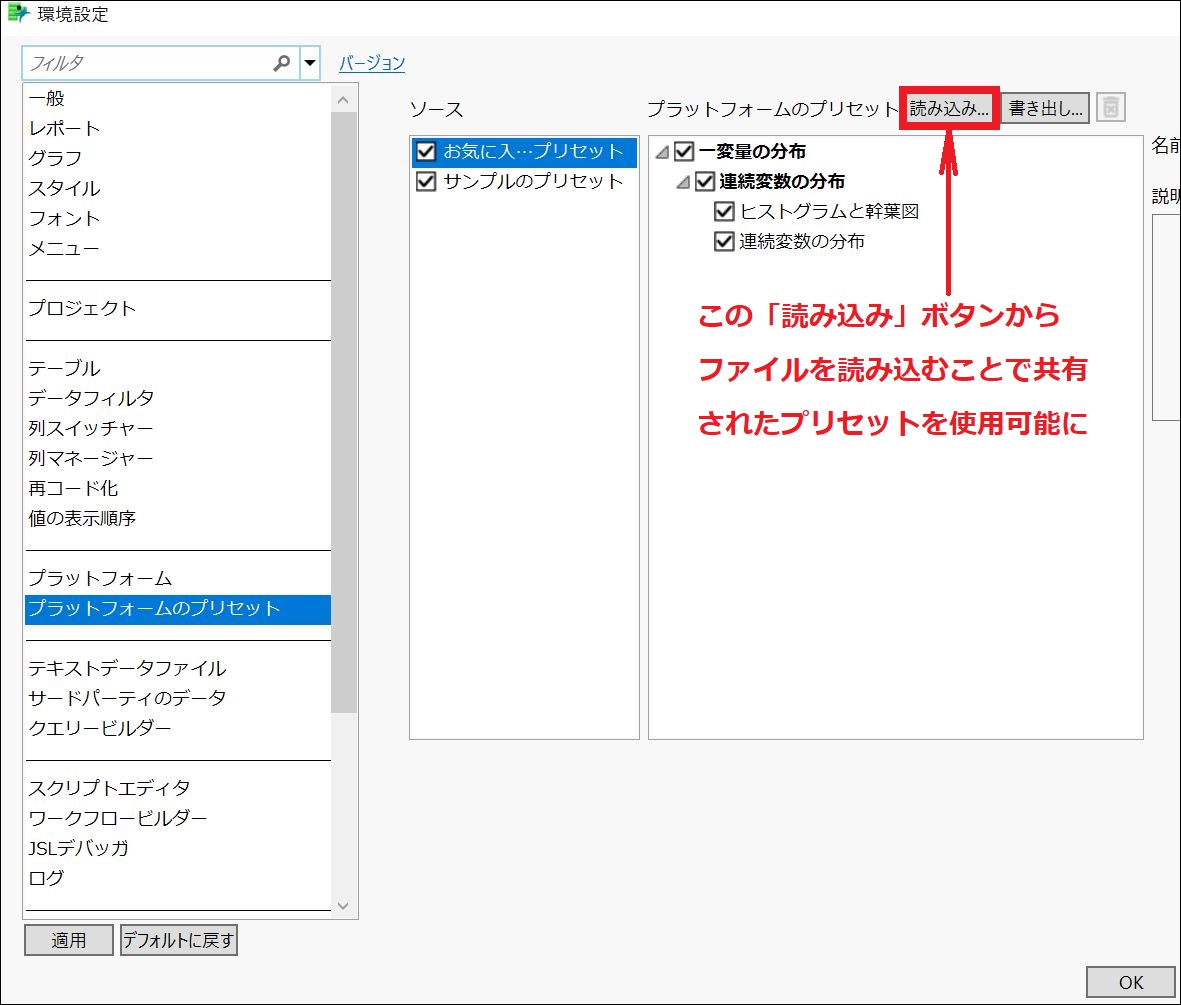
・読み込み
環境設定の同じ箇所で、「読み込み」ボタンをクリックし、プリセット形式のファイルを読み込みます。
毎回同じ設定やカスタマイズで分析を実施する方には、時間と労力を削減できるプリセットは大きな助けになるはずです。ぜひ試してみてください!
■JMP 18の新機能
https://www.jmp.com/ja_jp/software/new-release/new-in-jmp.html
4/22は「アースデイ」 環境保護活動をサポートするJMPのこれまで

毎年4月22日は「アースデイ」。
温暖化や環境問題に目を向け、個人や企業がそれぞれ行動を起こす日です。そして、1970年の初開催後、今や世界で10億人以上が活動やイベントに参加する特別な日になりつつあります。
近年、日本でもアースデイへの関心は高まってきています。たとえば、4/20(土)~4/21(日)には、渋谷区立宮下公園で「アースデイ東京2024」が開催され、クリエイター縁日や盆踊りを楽しみながら、さまざまな学びや人とのつながりを体験できるようですし、こちらのマップで家や職場近くのアースデイ関連イベントを検索することもできます。
また、イベントに参加する以外にも、この時期にあわせて海岸でゴミを拾ったり、リサイクル素材の服を選んで購入したり、個人でそれぞれに行動する人もいます。
そして、私たちJMPも組織として何ができるかを考え続けています。
【統計学習】無料なのに約30hのボリューム!著名企業でも活用されるオンライン統計コース「STIPS」

「統計やデータ分析を学んでみたい。でも、ネット記事やYouTubeには、いいコンテンツがない」
こう思って心が折れたことはありませんか?
文系出身で統計ソフト会社に勤める私もそうでした。
実際、インターネットには統計学習コンテンツが、それこそ無尽蔵に溢れていそうです。ですが、いざ探してみると、
・長尺の動画をいくつも観続ける必要がある
・動画内容の正確性に疑問
・テストがないため確認・定着が難しい
等の事情から、どれも一長一短。自分にピッタリなものが、なかなか見つかりません。学びたいのに適切な教材がすぐに見当たらないのは、本当にもどかしいものです。
一方、今回ご紹介する無料のオンライン統計コース「STIPS」は、米国発祥で30年以上の歴史がある統計ソフト「JMP(ジャンプ)」の統計エンジニアが作成しているので、内容は正確さと信頼性があると言えるかもしれませんし、説明、デモ、小テスト、演習がすべて含まれていて、およそ30時間程度で修了できます。
また、後でご紹介しますが、いま成長著しい企業として注目を集めるNVIDIAをはじめとして、国内外の数多くの著名企業様においても、社内学習プログラムとして採用いただいてきております。
それでは、「STIPS」の内容を少しご紹介しますね(急ぎの方は下の動画でも大丈夫です)。
約30hで統計知識が身につく!無料オンライン統計コース「STIPS」のご紹介
続きを読む3/14は「ホワイトデー」?いえいえ「円周率の日(Pi Day)」です。パイを食べてお祝いを!

今日は「ホワイトデー」ですね。朝からバレンタインのお返し準備に忙しかった方もいらっしゃるかもしれませんが、3/14は「円周率の日(Pi Day)」でもあるのをご存知ですか?
多くの国々で円周率(π)は、3.14159...であることから、3/14の01:59や15:09にお祝いをして、お菓子のパイを食べたり、πがない世界ならどうなっているか(どれほど不便か)を想像してみたり、思い思いにこの日を過ごすようです。
また、3/14は、「ホワイトデー」や「円周率の日(Pi Day)」の他に、アルベルト・アインシュタインの誕生日や、日本では「数学の日」(日本数学検定協会による。円周率の近似値であることから)でもあります。
続きを読む