“ラベルレス飲料”のメリットって何? 第1回 ~多重対応分析により、アンケート設問間の関連性をマッピング~
増川 直裕
■ポチっとしたことがきっかけに・・・・・・
先日、何となくECサイトを見ていたら、上の写真のようなラベルがない(ラベルレス)ペットボトルの水が、24個入りでセール価格になっていたため、思わずポチっとしてしまいました。
ラベルが貼っていない飲料「ラベルレス飲料」、皆様はどのようなことがメリットと考えますか?
どのような商品か分かっていれば、特にラベルがなくても不自由はないし、エコっぽいので、これからラベルレスの形態が広まっていくかもしれません。しかしラベルがないと、単体ではどのような商品かわからないし、成分表示などを知ることができないといったデメリットも考えられます。
ポチっとした後、注意してみるようになったからか、スーパーでも6本単位でラベルレス飲料が売られているのを見かけ、水だけでなくラベルレスのお茶が売っていることなど、ラベルレス飲料の知識が深まりました。
それならば、いっそのこと自分の特権(?)を生かして、JMPのお客様を対象にラベルレス飲料に関する調査をしてみて、得られた調査データをJMPで分析してみるセミナーを実施してみたら面白いのではとひらめきました。そこで昨年、主に食品、飲料業界におられる方を対象に、ラベルレス飲料に関する調査を実施しました。
本記事では、得られた調査データをJMPで分析したものの中で、皆様に紹介したい分析結果を2回に分けてご紹介します。
第1回目となる今回は、複数の質的(カテゴリカル)な設問の関連性を分かりやすく低次元にマッピングする多重対応分析(Multiple Correspondence Analysis)について紹介します。
アンケート調査では、性別、年代、はい/いいえで答える設問といった質的なデータを扱うことが多いので、多重対応分析は、調査結果を分かりやすくする手段として有効です。
■調査概要
今回実施した調査の概要は以下の通りです。

結果として、127名の方から回答を頂きました。
■回答の集計結果
まずは、設問項目のうちいくつかをピックアップして集計結果を示します。
Q. ラベルレス飲料を知っていたか(知っていた / 知らなかった)
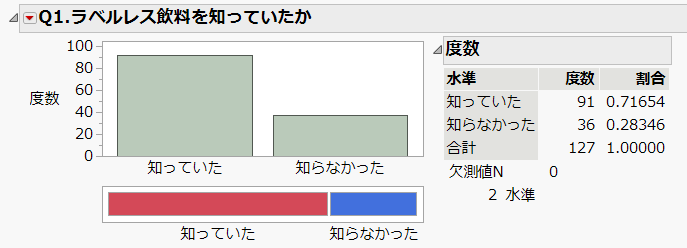
⇒ 約72%の方が、このアンケートを実施する前にラベルレス飲料を知っていたと回答がありました。回答者がこのアンケートをみたとき、自分は知らないから答えるのを止めたといった方もいらっしゃるかもしれないので、実際は、知っている割合はもう少し低いかもしれません。
さらに、アンケート回答者の半数以上は、食品、飲料業界の方です。そもそもこのような業界にいる方は、他の業界にいる方に比べて知っている可能性が高いとも言えますので、日本の大人全体を母集団と考えたとき、実際の知っている割合はさらに低いかもしれません(食品、飲料業界とそれ以外の方で知っている割合をカイ2乗検定で検定をすると有意差がつきます)。
Q. ラベルレス飲料を購入したことがあるか(ある / ない)
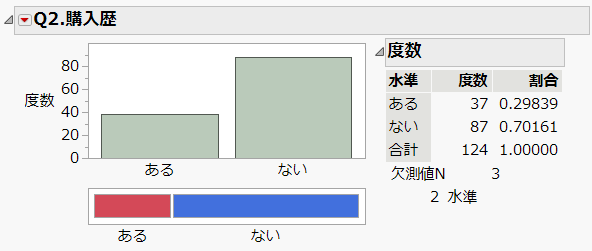
⇒ 30%ぐらいの方から購入したことがあると回答がありました。
Q. ラベルレスを購入するメリット (6つの選択肢、複数回答)
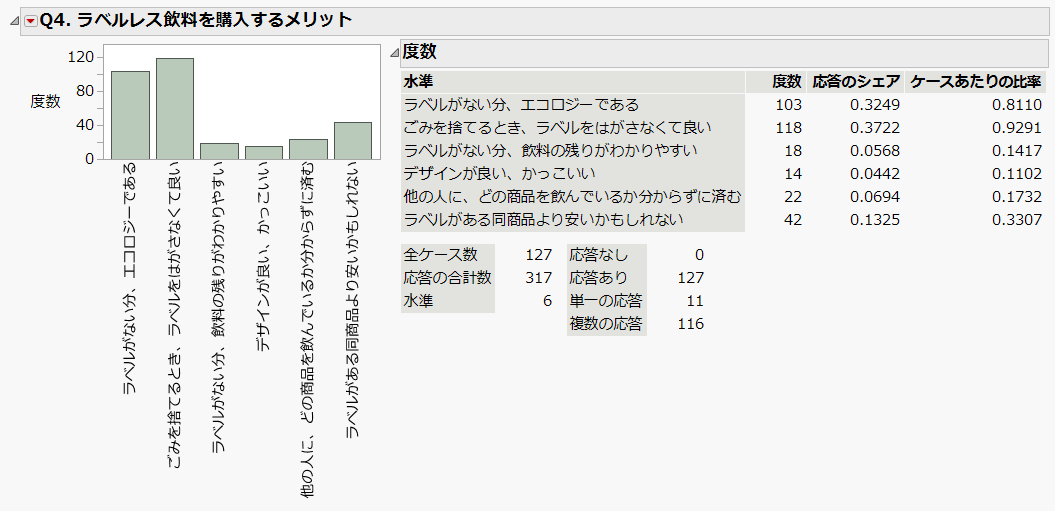
⇒ JMPでは列(変数)の尺度として「多重応答」というプロパティを設定することができ、複数回答の集計を簡単に行うことができます。
レポート右上に表示される「応答のシェア」は、全体の回答数に対する各回答の割合です。ここでは、各回答の度数を応答の合計数( = 317)で割り算しています。一方、「ケースあたりの比率」は、全体の回答者に対する各回答の割合です。ここでは各回答の度数を全ケース数( = 127) で割り算しています。
回答としては、”ラベルがない分、エコロジーである”、”ごみを捨てるとき、ラベルをはがさなくて良い” といったエコ的な回答をメリットとして感じている方が非常に多いことが分かります。
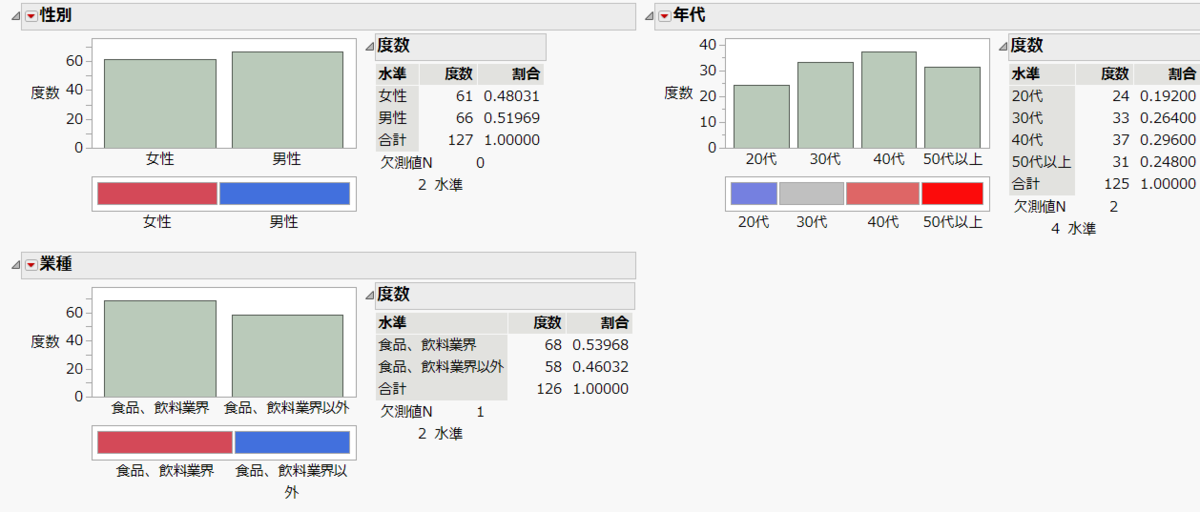
さらに、このアンケートでは、回答者の属性として、性別、年代、業種(食品/飲料業界、それ以外)を聞いていますので、これらの集計結果も示します。
■属性や設問間の関連性をみるには
ここまでは、設問ごとの集計結果を示しました。集計結果だけでも分かることが多いのは確かですが、”どのようなターゲット層にどのようなアクションをすべきか” を知りたいとき、属性と回答に対してクロス集計することが考えられます。
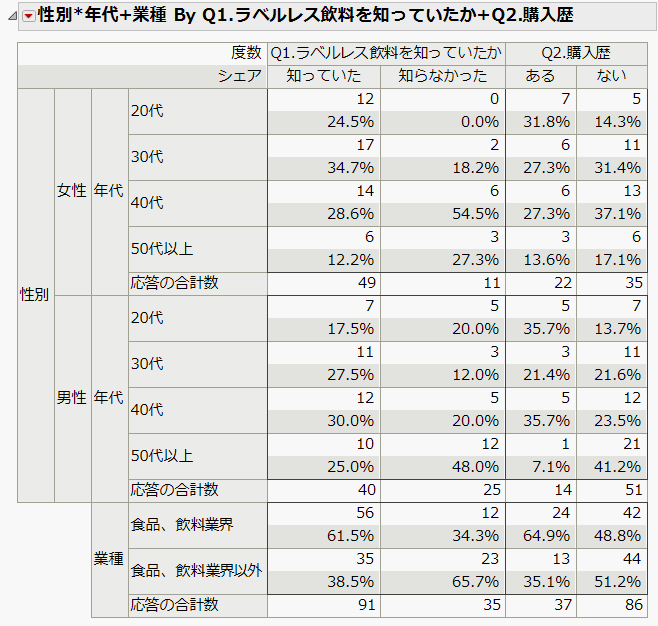
しかし、クロス集計は、設問の回答選択肢の数が多いときや、多くの設問をクロスして集計すると、例えば以下のような集計表になり、このような表を少し見ただけでは、属性ごとの回答の傾向が分かりづらくなります。
筆者は、このような表を見ると、頭が痛くなり、詳しく考察する気持ちが失せてしまいます・・・・・・
■多重対応分析で回答項目をマッピング
複数の設問間の関連性を分かりやすく把握する有効な統計手法として、多重対応分析(Multiple Correspondence Analysis, MCA) という統計手法があります。この手法は、コレスポンデンス分析と呼ばれることもありますが、アンケート調査のような質的(カテゴリカル)変数をもつデータを分析するときに有効な手法の1つです。
多重対応分析は、この手法の計算方法や理論的なことを考えると難しくなりますが、分析結果として得られる図をみるだけで結果を解釈すると割り切ってしまえば、統計の詳しくない方でも、分かりやすく結果を考察でき、他の人へ結果を伝える手段としても非常に有効です。
ここでは、先ほど集計結果として示した設問の回答や属性をすべて対象とし、JMPで多重対応分析を実施した結果を示します。
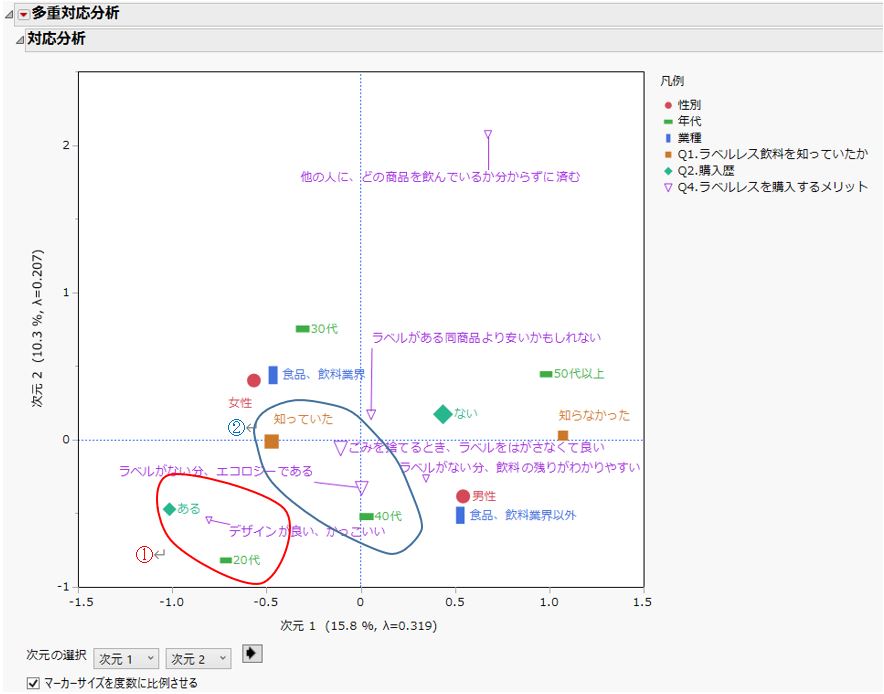
主な見方は以下の通りです。
- 図右上にある凡例のように、設問(属性も含む)でプロット点の色や種類を変えています。各プロット点は、その設問の回答選択肢(性別であれば”男性”、”女性”)になります。
- プロット点の大きさは、度数に(相対的に)比例させています。すなわち、そのカテゴリの度数が小さいときは点を小さく、度数が大きいときは点を大きくしています。
- プロット点が近くの領域に位置するカテゴリは、互いに関連していることを示します。
例えば、次のようなことが分かります。
- 図左下の①の領域(赤色の枠で囲んだ箇所)をみると、20代で購入歴がある方は、ラベルレス飲料を購入するメリットとして、”デザインが良い、かっこいい”と答えている人が相対的に多いことが分かります。
- ②の領域(青色の枠で囲んだ箇所)をみると、40代でラベルレス飲料を知っていた方は、ラベルレス飲料を購入するメリットとして、”ラベルがない分、エコロジーである” や ”ごみを捨てるとき、ラベルをはがさなくて良い” といったエコ的な視点を挙げている人が相対的に多いことが分かります。
- 右上に位置する ”他の人に、どの商品を飲んでいるか分からずに済む” といった回答の近くには、他のカテゴリが位置していないので、他の回答選択肢との関連性は低いと考えられます。(多重対応分析では、属性的な特徴がない少数意見の選択肢が、他の点とは外れた場所に位置することが多いです。)
このように多重対応分析を行うことによって、回答選択肢ごとに集計するだけではわからない知見を得ることができます。
■何を目的としてアンケート調査を実施するのか
結局のところ、企業側がアンケート調査をする目的としては、ターゲットとなるユーザ層を見つけたい、商品の満足度を調査し改善点を探したい、商品間の満足度の比較をしたいなど、単純な集計だけでは目的にアプローチできる結果が得られないことも多いです。その際、1つの手法として、多重対応分析を実施してみたらいかがでしょうか。
次回の第2回では、ラベルレスを推奨する人(しない人)を特徴づける属性や回答を探索的に見つけていった結果を紹介します。
さあ始めましょう。最新版JMP 16 のダウンロードは下から!